
I’ve been doing a lot of AI-assisted coding this year, and somewhere around the hundredth “just write this real quick” request that spiraled into a multi-session debugging odyssey, I realized I needed an actual workflow. Not a tool. Not a prompt. A process — one that works for me and for whatever agent happens to be in the driver’s seat.
A note on scope before we start. What follows is the harness I use for work that requires careful planning and stepwise resolution — non-trivial features, refactors that span multiple files, anything where getting the design wrong cascades into hours of cleanup. It is not the right tool for standard ops tasks (restart this service, rotate a credential), one-off debugging sessions, or simple changes a single agent run can finish in five minutes. For that class of work I use the agent directly, no harness. Reach for this when the cost of doing it wrong is higher than the cost of setting up the harness — not before.
What emerged has three layers: plan with a spec-planner, track everything through a task tracker (in my case Linear), and implement through a supervisor that delegates to non-reasoning models in isolated workspaces. Here’s how each piece works, what they talk to each other about, and what I still haven’t solved.
1. The Task Tracker as the Spine#
A ticket in a task tracker is the entry point for everything that follows. Tickets get born from anywhere — a conversation with an agent, an exploration session, a postmortem, a code-review finding, a deliberate planning round — but once a ticket exists, it becomes the contract every downstream agent reads from. The spec-planner expands the ticket into OpenSpec artifacts. The implementation-supervisor then works against those artifacts, with the ticket serving as the state spine — it gets transitioned to In Progress when a PR opens, and to Done when work merges. Bot reviewers reference the ticket in PR comments. Every artifact ties back to one.
So the tracker isn’t a sidecar. It’s the spine.
I’m using Linear for this. It’s free for solo use, has a clean GraphQL API that an agent can drive without screen-scraping, and the workflow primitives (states, priorities, parent/child links, comments) map almost 1:1 to what the agents need. Pick whichever tracker satisfies those constraints — the workflow doesn’t care, as long as the tracker is API-first.
The diagram is the workflow in one frame: tickets flow in from anywhere at the top, the ticket itself is the spine in the middle, and the two agents read and write against it on the way down — with OpenSpec artifacts as the only handoff between them.
This shape is what makes the rest of the workflow possible. Without a single source of truth that every agent agrees on, you end up with the agent equivalent of a Slack thread: lots of activity, no shared state.
A few things make this work in practice:
What the agents need to know#
Ticket lifecycle transitions. The implementation-supervisor has hardcoded rules for when to transition a ticket. PR opened? Move to In Progress. Human says “merged”? Move to Done. Bot review findings that are out of scope? File a linked follow-up ticket with priority set. These transitions are triggered by concrete events, not vague judgments — the agent doesn’t have to decide when to update the ticket. The rules tell it.
Priority on filed follow-ups. When an agent discovers a bug that’s out of scope for the current ticket, it files a follow-up ticket. Without priority, those follow-ups sit in a pile and I have to re-read every one to figure out what’s urgent. The rules force the agent to assign priority: Medium for HIGH-severity findings, Low for MED, No priority only for truly deferable nice-to-haves. This matters because I’m treating the backlog as a scheduling queue, not a graveyard.
API, not UI. The agents don’t click around — they call the tracker’s API directly (Linear’s GraphQL endpoint, in my case). I wrote a handful of small skills — linear-connect, linear-verify-record-issue, file-linear-followup — that wrap the common operations. The key design choice is that these skills don’t try to be generic “manage Linear” tools. They’re workflow-specific: connect, verify-and-file, file-followup. Each does one thing the workflow actually needs. If you swap trackers, you swap the skill implementations; the workflow contracts stay the same.
2. The Spec-Planner: Explore, Grill, Propose#
A ticket on its own is just intent. The spec-planner is what turns “PER-156: rework credential resolution” into a plan that an implementation agent can actually execute against. It reads the ticket, expands it through three phases, and writes OpenSpec artifacts back into the repo.
It’s a three-phase agent, and the middle phase is the one that does the real work.
Phase 1: Explore#
The agent acts as a thinking partner. I bring a vague problem — “the credential resolution is getting messy across three repos” — and it opens up the space. ASCII diagrams, 2-3 possible directions, codebase reads to stay grounded. It surfaces tradeoffs but doesn’t push for decisions. The goal is to find the shape of the problem, not resolve it.
This phase is deliberately permissive. No commitments are made. If a decision crystallizes, the agent offers to write it down but never captures without asking.
Phase 2: Grill (the important one)#
This is the customization. Once a direction is chosen, the agent switches to relentless interview mode. It walks a decision tree — every branch implied by the chosen direction — and resolves one at a time. No stacking questions. No moving on without a concrete answer.
The rules:
- Recommend an answer for every question. The agent never asks open-endedly. It presents choices with a recommended one flagged and a one-line justification. My job is to confirm, override, or tell it to think harder — not to invent answers.
- Prefer the codebase over the user. If a question can be answered by reading code, configs, or existing artifacts, it reads them instead of asking. Only surfaces findings if they change the plan.
- Push back on vagueness. “Whatever you think” gets refused. The agent restates the decision, the recommendation, and why it matters, and forces a concrete choice.
- Track the tree visibly. As branches close, it summarizes what’s been decided. Uses a task tracker for the decision tree if it gets deep.
- No silent assumptions. If it has to assume something, it states it out loud: “assuming X; object now or it becomes a design decision.”
This phase was inspired by Matt Pocock’s original “grill me” skill — the idea that an agent should interrogate a plan until every edge case is covered, not just nod along. The original skill is incredibly short (just a few paragraphs) but powerful: it shifts the agent from a passive executor to an active challenger with a single instruction. I adapted it into a structured decision-tree walker that’s now baked into the spec-planner as a mandatory phase. I’ve found that without this phase, plans are structurally complete but edge-case incomplete. The spec says to add a CLI command but doesn’t ask what happens when the target file is missing. The design lists happy paths but not empty states. The grill phase catches those before the implementation agent gets dispatched, which saves multiple review rounds and follow-up tickets — the worked example below shows what that looks like when it works (one decision made during grilling prevented a regression that would otherwise have cost a full bot-review round).
A real grill session looks like this — branches from the PR #159 planning round, simplified:
Three things this picture makes concrete that prose doesn’t:
- Every node has a recommended answer. The agent doesn’t ask open-endedly. The user’s job is to confirm, override, or push back — not to invent.
- The exit gate is enumerable. “15 confirmed · 0 deferred · 0 silent assumptions” is the literal exit criterion. You can’t leave the phase with hand-waves.
- One of those nodes — a question about how the autofix should rewrite paths — turned into the design decision that prevented a Medium bot finding in the worked example below. The picture shows where the saved review rounds come from.
Phase 3: Propose#
Once every branch is resolved, the agent formalizes everything into OpenSpec artifacts: proposal.md, specs/, design.md, tasks.md. These are machine-readable and become the input to the implementation supervisor. If my /opsx-enhance-tasks skill is installed in the project, it layers on TDD test cases, phase-level goals and validations, and repository/branch strategy — turning the tasks into something an implementation agent can actually execute against. This is optional; for simple features or straightforward logic, the vanilla OpenSpec artifacts are often enough.
OpenSpec specifically isn’t load-bearing here. I picked it because I was already using it before this workflow harness existed, and it turned out to be open enough that I could customize around it (hence /opsx-enhance-tasks and the rest of the opsx-* skill family). Any spec format that produces machine-readable artifacts the implementation supervisor can ingest would work just as well — OpenSpec just happened to be what was already on my desk.
(The opsx- prefix on my custom skills is just a naming convention so they sort next to OpenSpec’s own commands — nothing magical about it.)
The full flow: Explore → Grill → Propose → (Enhance). Skipping Grill is how you get a 7-commit PR with bot review findings out the door.
3. Implementation Supervisor: Rigid Phases, Clean Context#
Once there’s a spec and a Linear ticket, the implementation-supervisor takes over. Its philosophy is simple: the supervisor’s context stays pure — design and review only. Implementation is always delegated.
This separation is the core architectural decision. Opus-grade models (the supervisor) are strong at critical thinking, instruction-following, and catching subtle mistakes. Non-reasoning models (the delegates) are fine at mechanical edits but sloppy on intent. Splitting design from implementation keeps each model doing what it’s best at, without polluting the expensive model’s context with implementation details.
The shape looks like this:
The whole diagram has two takeaways:
- Two lanes touch in only two places. A prompt goes down, a diff comes back. The supervisor never reaches into the delegate’s worktree, and the delegate has zero conversation context to reach back with. That’s the entire isolation contract.
- The supervisor lane is itself a small pipeline. Setup → build prompt → deep review → merge/PR. Steps 0–8 in the list below are the granular implementation, but the conceptual shape is four phases bracketing one delegation.
Now the list, for when you want the actual mechanics:
The phases#
Step 0 — Mode and delegate selection. Two orthogonal choices: copilot (per-step human gates, the default) or auto (one human review at the end via GitHub PR UI). And delegate-to-oc (OpenCode with non-reasoning models like kimi or deepseek) or delegate-to-cc (Claude Code with sonnet, for delegations that benefit from a slightly stronger code model). These are set once and drive everything downstream.
Step 1 — Scope confirmation. In copilot mode, the supervisor interviews me: which ticket, which repo, is there an OpenSpec change, which delegate model. In auto mode, it reads scope from the existing OpenSpec change and proceeds without me. Either way, a feat branch is created off main before dispatch — PR flow is the default exit path.
Step 2 — Verify codebase claims. The supervisor reads the OpenSpec change, then greps the codebase to confirm every file path, line number, and string the spec mentions. If anything is stale, it stops and asks. Saves the delegate from discovering broken assumptions mid-implementation.
Step 3 — Build the implementation prompt. This is where the supervisor earns its keep. If an OpenSpec change exists, it’s an auto-stub — the supervisor skips hand-writing. Otherwise, it authors a detailed prompt containing: the relevant OpenSpec tasks, a confirmed codebase inventory (file lists, grep results it already ran), an explicit execution plan with exact commands, worktree-relative verification commands, an output contract (structured reply format), and out-of-scope guardrails (identifiers and files the delegate must not touch). The delegate has zero conversation context — everything must be in the prompt.
Step 4 — Dispatch and wait. The delegate runs in an isolated git worktree under tmux. No shared state with the main repo. The supervisor polls a sentinel file, then reads the answer. The tmux session is kept alive so I can attach and watch if I want to.
Step 5 — Deep review. This is the supervisor’s real job. A 14-point checklist that includes: acceptance grep (do the claimed changes exist?), verification commands (do tests pass?), diff sanity (any files outside scope?), substring collision (did a rename silently eat a reference?), branding leaks, lockfile regeneration, endpoint echo (is the delegate writing to the right environment?), and OpenSpec tasks.md checkbox state. Every check gets one of pass, fail, or n/a, and a check left out of the output is a failed review.
Step 6 — Present findings. The supervisor prints a structured review block with status, diff stats, the full deep-review checklist results, verbatim verification output, and a recommendation: accept, iterate, or reject. In copilot mode it then asks “Accept and merge?”
Step 7 — On accept: merge and PR. The default exit path. Feat branch is pushed, PR is opened, Linear ticket is transitioned to In Progress with a comment containing the PR link. Then the supervisor polls the opencode-review bot, triages findings by severity, and iterates on fix-ups until the bot returns clean. Only then does it hand the PR to me for UI merge. When I say “merged,” the supervisor transitions Linear to Done.
Step 8 — On reject: leave everything intact. If I reject the changes, nothing is cleaned up. The worktree, tmux session, and branch all stay alive so I can inspect or fix in place. This is important — a cleanup-happy agent destroys the evidence you need to understand what went wrong.
A Real Run: PR #159#
Abstract patterns are easy to argue with, so here’s an actual run of the workflow that’s currently sitting open in front of me as I write this.
The change: gate-artifact-reference-paths in agentic-beacon. Markdown links inside warehouse artifacts were being written as filesystem-relative paths — fine for the author, broken for every downstream consumer the moment artifacts got distributed via symlink. The fix: a canonical link form, a lint that enforces it, an autofix that migrates existing artifacts, and an integration test proving links resolve after a real abc sync. Also folds in a related sub-ticket about partial wiring.
Final size: 31 files, +2018 / -822 lines, 12 commits across 4 phased delegations, 3 bot review rounds.
Step 1 — The ticket existed first#
The work started as Linear ticket PER-206: “Resolve and gate artifact reference paths so markdown links survive distribution”. It was filed weeks earlier from a postmortem about a downstream agent failing to resolve cross-artifact references.
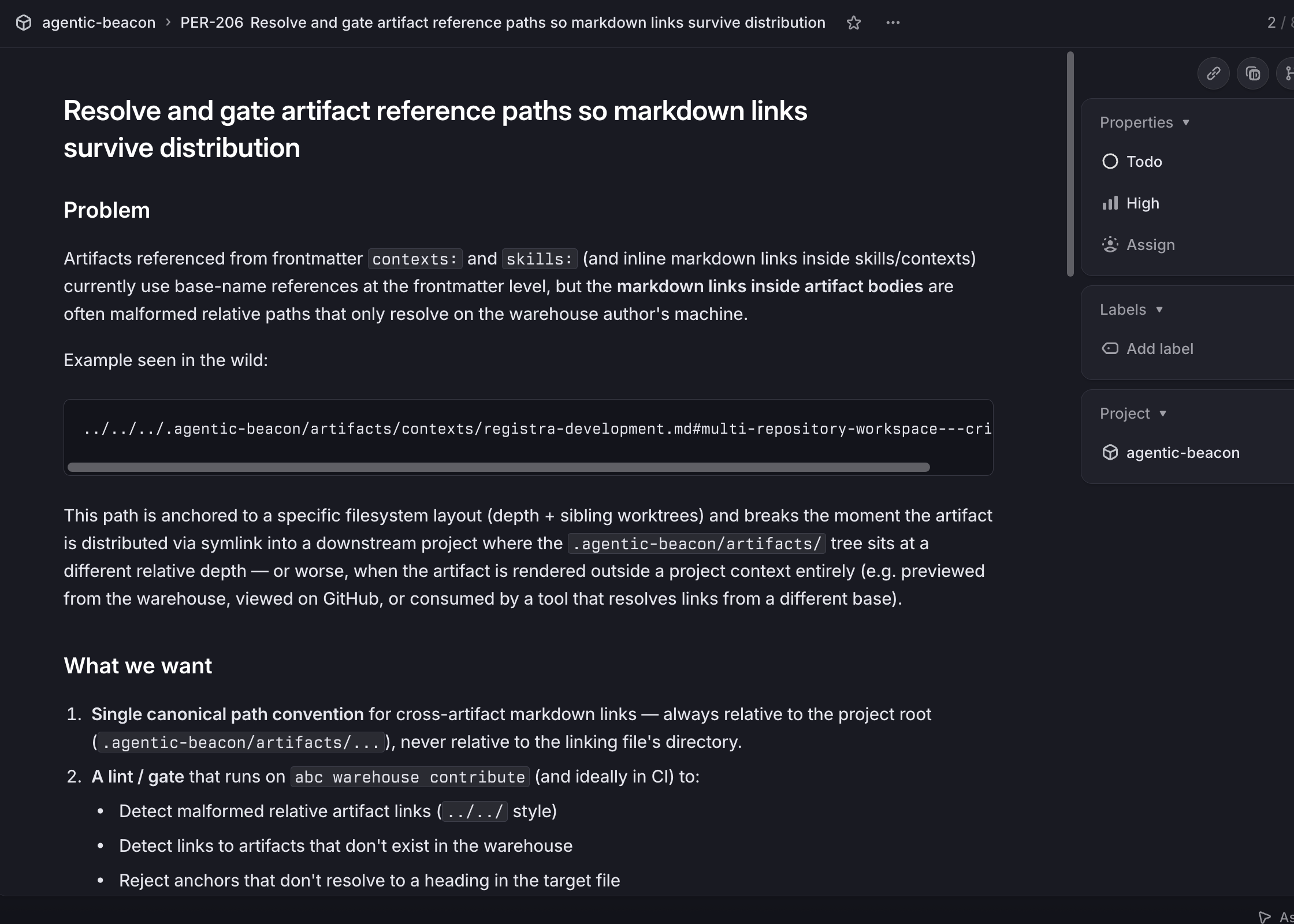
The ticket sat in Todo for a while, getting refined as I noticed related issues. One of them — PER-238, “OpenCode exposes agents/_partials/* as callable subagents” — turned out to share a root cause (partials being distributed into the wrong directory tree), so the parent ticket eventually absorbed it.
Step 2 — Spec-planner expanded the ticket#
Once I had bandwidth, I invoked the spec-planner against PER-206. Explore phase produced two candidate link conventions (project-root-relative vs. always-canonical-from-warehouse-root), with diagrams of how each would resolve in three downstream layouts. I picked the first.
Grill phase walked the decision tree:
- What about anchors with duplicate headings? → “GitHub-exact slugify with
-Ndedup.” - What about a relative link inside a skill’s own folder? → “Allowed — bundled assets travel together.”
- What about links that escape the warehouse root entirely? → “Hard error, no autofix — human decision.”
- Should
--fixrewrite the link label or only the target? → “Target only. Span-based slicing.” (this exact decision later prevented a Medium bot finding in round 2 — see below)
Fifteen branches resolved. The agent then ran /opsx-propose to generate proposal.md, design.md, tasks.md, and a specs/ capability under openspec/changes/gate-artifact-reference-paths/. The tasks file came out to 400 lines across 7 phases with TDD test cases per task.
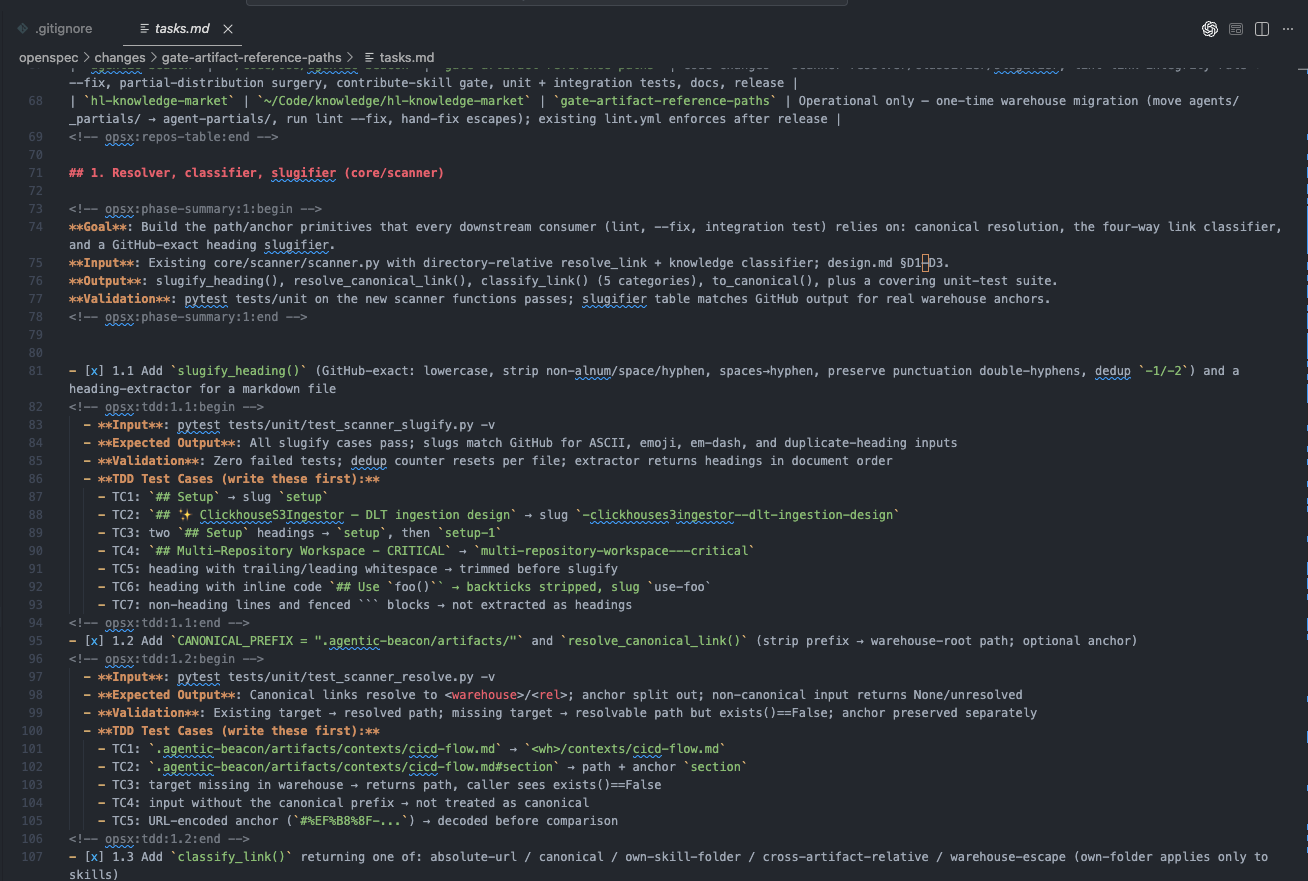
Step 3 — Phased delegation#
Because the change touched scanner primitives, lint rules, distribution code, and docs, dispatching it as one delegate run would have been a context disaster. Instead I dispatched it in four sequential phases, each with the supervisor’s full review cycle:
| Phase | Scope | Commit |
|---|---|---|
| 1 | scanner canonical-link primitives (slugify_heading, classify_link, resolve_canonical_link) | 0424190 |
| 2-3 | lint integrity rules + --fix autofix | 2770219 + 0e4188d |
| 4 | partial restructure (closes PER-238) | 7ff89ea |
| 5-7 | contribute gate, integration test, canonical-link docs | c3fdfe0 |
Each phase: feat branch already in place → supervisor authored the prompt from the OpenSpec tasks → dispatched to a delegate in an isolated worktree under tmux → I attached and watched when I felt like it → supervisor ran the 14-point deep review on the diff → I accepted → merged into the feat branch with --no-ff to preserve provenance.
The dispatch status block for phase 1 looked like this (real output, paths redacted slightly for the post):
## Delegation dispatched — gate-phase1
Model: litellm-responses/chatgpt/gpt-5.4
OpenSpec: gate-artifact-reference-paths
Repo: /Users/.../agentic-beacon
Branch: delegate/gate-phase1 (off feat/gate-artifact-reference-paths)
Worktree: /tmp/oc-delegate/worktrees/agentic-beacon/gate-phase1
tmux: oc-delegate-gate-phase1
Answer: /tmp/oc-delegate/gate-phase1.answer
Sentinel: /tmp/oc-delegate/gate-phase1.sentinel
Tmux log: /tmp/oc-delegate/gate-phase1.tmux.log
Prompt: /tmp/oc-delegate/gate-phase1.preambeled.md
Attach: tmux attach -t oc-delegate-gate-phase1
Detach: Ctrl-b d
Kill: tmux kill-session -t oc-delegate-gate-phase1Once the feat branch had all four phases merged in, it got pushed and PR #159 opened against main. PER-206 transitioned to In Progress automatically with a Linear comment containing the PR link.
Step 4 — Three bot review rounds#
This is where the workflow earns its keep. Every push to the feat branch triggered the opencode-review workflow, which runs a separate review agent against the diff and posts findings as a PR comment. The supervisor polled for the bot result, triaged each finding by severity, and either folded a fix-up commit into the same PR or filed a follow-up Linear ticket.
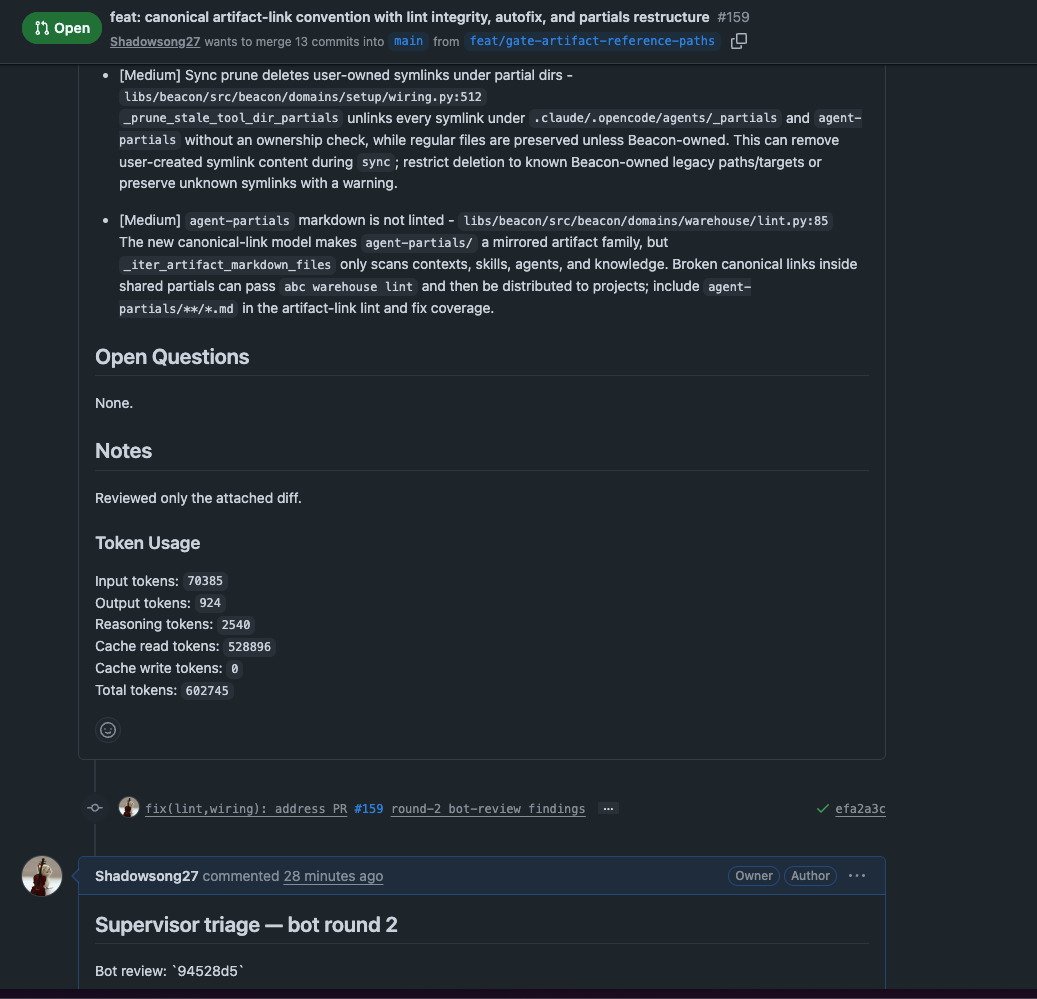
Round 1 — bot found one HIGH, two MEDIUM, one LOW. Supervisor’s triage comment (verbatim from the actual PR):
HIGH — Canonical knowledge links can pass lint but remain broken after sync (
scan_file_for_knowledge).
- Decision: filed as PER-241 (High priority). Out of scope for this change per OpenSpec task 2.4 ("
scan_file_for_knowledgeSHALL NOT be modified — sync stays warning-only"), but blocks the warehouse migration. Already documented in this PR’s description (Known limitation), in the test fixture comment, and in the merge commit body. Must land before the warehouse PR.MEDIUM — Partial pruning is not atomic with agent wiring.
- Decision: acknowledged, no behavioural change — fixed in
94528d5by adding an inline rationale comment. The current ordering is a deliberate design choice […]MEDIUM — Warehouse link policy in
core/scanner/rather thandomains/warehouse/.
- Decision: acknowledged, no action. This is the pre-existing architectural pattern […]
LOW —
_print_lint_reportdetected--fixviasys.argv.
- Decision: fixed in
94528d5by extendingLintReportwithfix_requested: bool = False[…]
That HIGH finding becoming PER-241 is a workflow detail worth pausing on. The supervisor’s rule says: when a bot finding is genuinely out of scope but worth tracking, file a Linear ticket with priority set, link it in the PR comment, and never silently defer. The follow-up ticket appeared in my backlog with High priority while the parent PR continued.
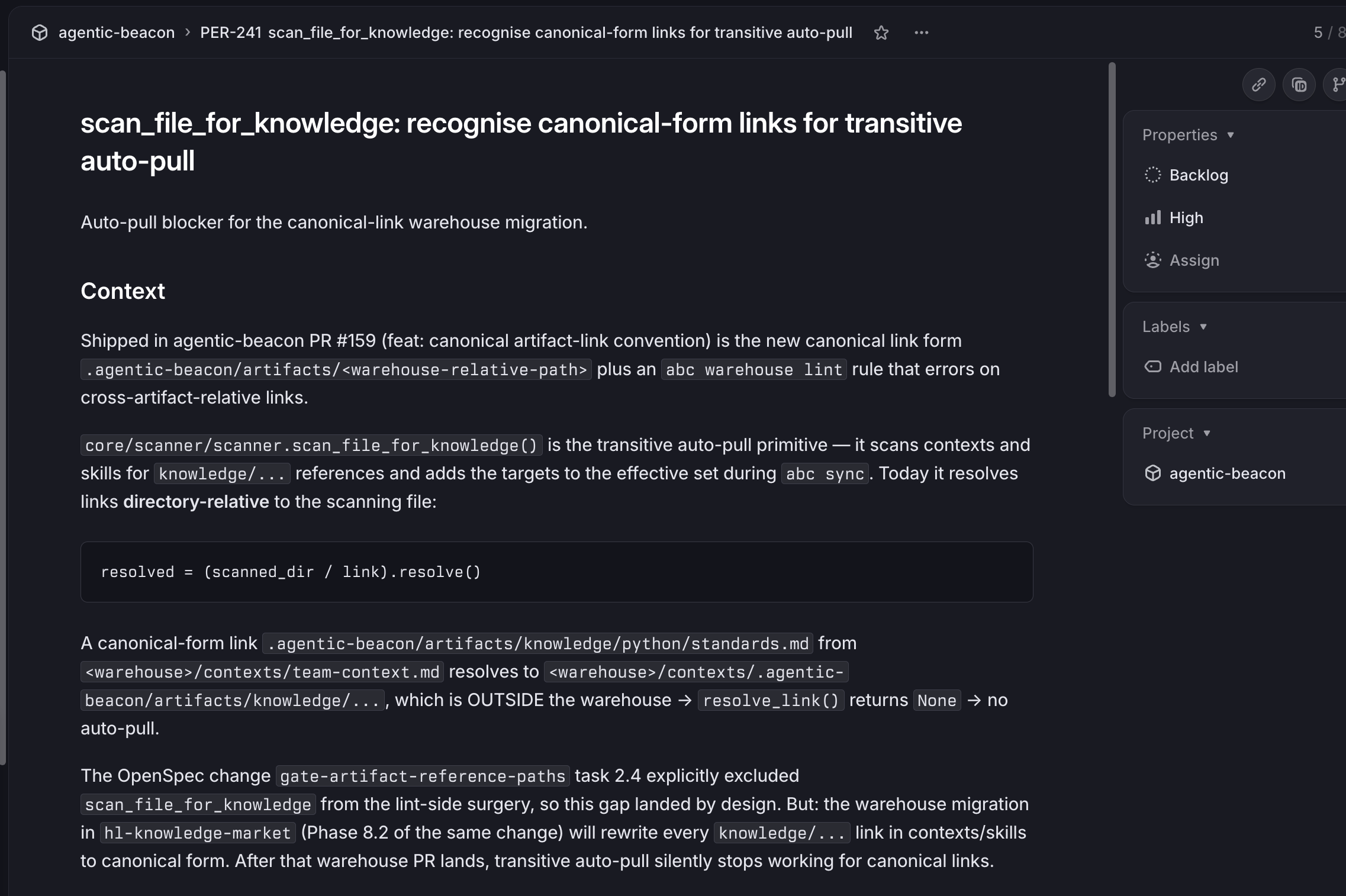
Round 2 — bot reviewed 94528d5, found three new MEDIUMs (one of them a regression from the round-1 fix, which is exactly the kind of thing bot-after-fix iteration catches). One example, verbatim:
MEDIUM —
--fixcould rewrite the link label instead of the target (lint.py:477).
- Decision: fixed in
efa2a3c+ regression test (test_fix_does_not_rewrite_label_when_label_matches_target). The naivefull_text.replace(group(2), ..., 1)finds the first occurrence anywhere inside[label](target), so for[../../contexts/bar.md](../../contexts/bar.md)it rewrote the label and left the target malformed. Replaced with span-based slicing so only the parenthesised target is rewritten.
Three regression tests added; commit efa2a3c pushed.
Round 3 — bot reviewed efa2a3c. Clean. No findings above LOW.
At which point the supervisor handed control back: PR is bot-clean, awaiting human UI merge. PER-206 still In Progress, will transition to Done when I merge.
What this run shows about the workflow#
A few things stand out re-reading this end to end:
- The task tracker really is the spine. PER-206 was the ground truth in Linear. The OpenSpec change was named after it, the feat branch referenced it, the PR closed it, three different bot rounds referenced findings against it, and one follow-up (PER-241) was born from it. Every artifact ties back to a ticket.
- Phased delegation matters. A 31-file change as one delegate run would have been a mess. Four phases, each ~250-700 lines, each independently reviewable.
- The grill phase paid off. The decision about
--fixrewriting target vs. label was made during grilling. The bot still caught a regression in round 2 because the implementation of that decision was wrong, but the design was correct — the fix was small. - The bot review loop is genuine review labor. Three rounds, six findings folded into the PR, one filed as a follow-up. None of that came from me reading the diff line by line. I read the supervisor’s triage comments and approved decisions.
- The HITL gate is at the end. The whole multi-day flow only stops for me at three places: scope confirmation per phase, accept-or-iterate per phase review, and final UI merge. Everything between those is autonomous.
The PR is still open as I publish this. If you click through and it’s merged, you can also see the final supervisor comment with merge SHA and the Linear → Done transition.
What I Haven’t Solved#
Three specific limitations are worth naming. The first two are inherited from OpenSpec’s task model; the third is a harness gap I haven’t filled yet. None of them are solved.
Mixing ops tasks with implementation tasks#
OpenSpec’s tasks.md is a single flat list, and in practice my changes mix three task types: implementation (produces a PR), devops (runner config, CI, secret rotation), and dataops (migrations, backfills, dbt promotions). The implementation-supervisor only handles the first cleanly — every ticket assumes a PR-flow exit. Ops tasks get done but don’t track the same way: no PR, no bot review, no tasks.md checkbox lifecycle that naturally mirrors a merge.
When a change has both feat and ops tasks, I either run the supervisor against the feat tasks and do the ops manually (losing the audit trail), or try to shoehorn ops into a delegate run (which works mechanically but the verification model is wrong — a migration’s “done” condition is a verified database state, not a passing test).
I haven’t found a clean way to manage them properly within one list.
Cross-repo work#
OpenSpec changes are repo-scoped: one openspec/changes/<id>/ lives in one repo. Real cross-repo work — add a field to the schema in repo A, consume it in repo B — doesn’t map cleanly to one change. I’ve tried two approaches:
- Split into multiple OpenSpec changes, one per repo, linked by a single Linear ticket. Mentally hard to track — I lose the “this is one piece of work” thread. One ticket → one change is much easier to hold in head.
- Manage from one repo — pick the primary, write the OpenSpec change there, treat the other repo as a follow-up dispatch. The supervisor handles this via sequential delegations with
-step1/-step2ticket suffixes. Works but the spec doesn’t capture the cross-repo coupling — the design intent for the second repo lives only in the dispatch prompt, not in any artifact.
I’ve settled on the second approach but it’s a tradeoff, not a solution.
Multi-ticket coordination#
The harness handles one ticket at a time. There are two adjacent gaps it doesn’t address.
The first is dependency ordering across tickets: there’s no way to express “PER-180 must land before PER-181” inside the harness itself. I sequence in my head, or I daisy-chain by setting up the second ticket’s OpenSpec change to reference the first one’s merge SHA. Neither feels durable — when I come back to a half-done stack two weeks later, the ordering lives only in my recollection.
The second is fan-out from a single intent: if I want to run “rotate the credential resolution module everywhere it’s referenced,” there’s no clean way to fan that out into a coordinated set of child tickets that the supervisor can dispatch in batch. Each child has to be invoked individually, and the parent intent doesn’t live anywhere except in the original conversation that produced the tickets.
Both gaps point at the same missing primitive — a project- or epic-level object above the ticket. Linear has the abstraction (Projects, Initiatives), but the harness doesn’t read or write at that level. Exposing it cleanly is on the list, just not done.
A Note on Why I Bother#
Building and refining this harness has eaten a non-trivial amount of my time this year. People reasonably ask whether it’s worth it — wouldn’t you ship more by just typing prompts and accepting whatever comes back?
My honest answer: in this wave of agentic AI adoption, sharpening the harness around the agent is just as important as the work the agent ships through it. Models change quarterly. Skills, supervisors, prompt patterns, evaluation loops — those compound. A workflow that produces clean PRs with kimi today produces cleaner PRs with whatever-replaces-kimi next quarter, with no rewrite. The harness is the durable artifact.
There’s a second reason that matters more to me: you learn more by riding along than by waiting on the sidelines. Every weird failure — a phased delegation that almost merged a half-stale OpenSpec, a prompt-review gate I built and then quietly retired, the OpenSpec-doesn’t-handle-cross-repo gap — taught me something about how these systems actually behave under load. None of that shows up in a vendor blog post or a Twitter thread. It only shows up when you’re shipping real work through your own setup.
And honestly? It’s just more fun this way. Watching a delegate run end to end in a tmux pane, triaging bot findings against your own triage rules, catching a regression in round 2 that your grill phase predicted in round 0 — that’s a different kind of engagement than copy-pasting into a chat box. The harness turns AI-assisted coding into something that feels like building, not consuming.
If the wave keeps going, the people who will be furthest along in two years aren’t the ones using the best models. They’re the ones who built the best harness around whatever model happened to be on hand.