DE Log 2.1: Develop Data Science Project in Production
Recently I was working on the deployment of a predictive model built by my dear friend valued ex-colleague. Here I will share some thoughts and challenges I have encountered during its production deployment.
This topic will be discussed over at least two blog posts, as I do not write a super long article and then give up before I can finish it (Heck I almost did not finish this one). I will discuss the entire system, from the preparation of data and model artifacts to the deployment of the actual service.
Essentially, the service itself will load the artifacts and doing real time prediction based on information posted by the frontend, and the update of the models/other datasets is done at a scheduled interval.
Disclaimer: I am working in a startup, that means the size of data is not as huge as Facebook or Twitter, some strategies adopted here may not be realistic in your context, and I am sure I have not yet encountered every problem in the field so this is not a guide, it’s just to share some thoughts.
Architecture
The development generally could be divided into two big parts:
-
Data and model preparation pipelines
-
Service Development
This preparation step is done at a scheduled interval.
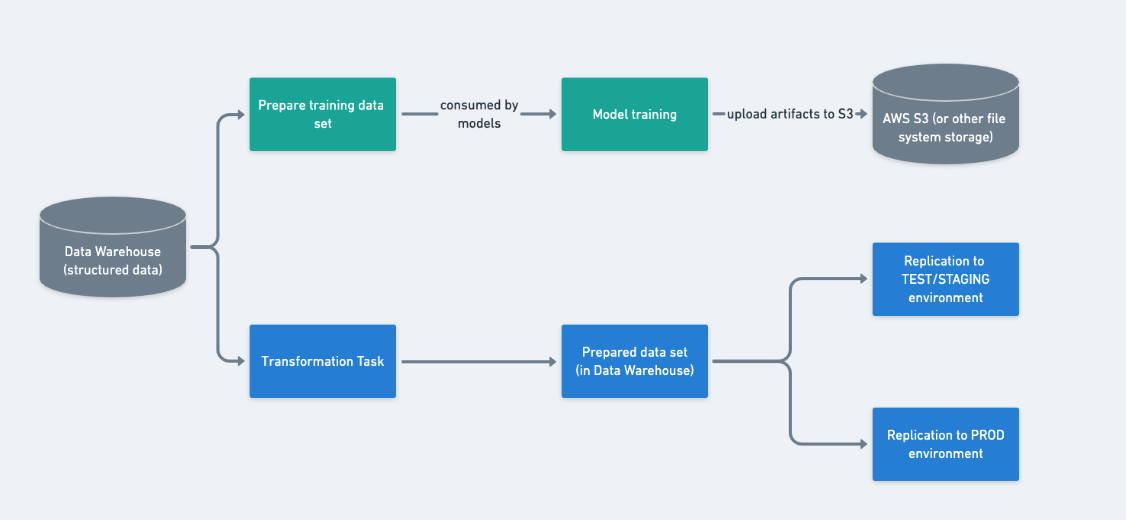
As illustrated by the diagram above, we are mainly doing
-
At the start of each month (or week or day depend on the business need and marginal gain of incremental learning), prepare the data -> train the models -> save the model artifacts for future use.
-
At an independent but often much shorter interval, prepare the additional data sets needed for prediction from Data Warehouse, and then they would be further replicated to the service backend for later use.
Model Preparation
It is pretty straight forward, politely ask your data scientist colleague to organize the commands to prepare, train the model. If your dear friend and valued colleague does not know how to do that, help them by wrapping the code with a CLI command interface.
One very important thing to note:
Some parts of the data science project such as prediction function or other data processing functions will inevitably be reused in the backend service. While preparing the commands for scheduling, I would package those necessary tools into a separate folder, decoupled from memory intensive libs such as pandas (still in the same repo), and later on built by running pip install git+ssh.
root
|____prediction_model
| |____stuff for model training
| |______init__.py
|____prediction_model_tools
| |______init__.py
| |___ stuff for production use
|____README.md
|___ setup.py (setup for prediction_model_tools folder)
People who are improving the model might forget to update the production tools, it is vital to setup tests for those production tools, mainly on the shape of input. The accuracy test of the model should also be installed so that we do not deploy a worse model into production (if not using incremental learning). More details will be discussed during the deployment phase.
Data Preparation
Normally it is just data transformation, within Data Warehouse, nothing much to talk about. Complexity might vary depends on your usage and source data. However, we do need to think about the feasibility of TRANSACTIONAL queries in a production environment. Let’s say we prepared an analytical table prejoined that has 1 billion rows, which is easily handled by any modern data warehouse. However, when you want to serve them in a standard Postgres instance, you will need to think about the tradeoffs. Will a normal select be slow? How should we index it (Data replication does not usually handle indexin)? Should we prepare everything in one table and simplify the ORM layer / raw SQL layer or should we do custom joins on a needed basis. Anyway, the core idea is to think about the feasibility when replicating the data. It would be easier if the data engineer has some background in transactional queries, or even the optimization of the service databases.
A Note on Data Replication
We do not serve data directly from data warehouse as it is brittle, not ACID (Redshift and many File System based Data Warehouse), this should be a common understanding so I will not further explain the need to replicate data.
However, I would like to stress the importance of having the same data set being replicated to both the TEST and PROD environment. It ensures the reproducibility of certain data bugs.
In development environment, I would suggest a direct connection to data warehouse if your service is not crazy at opening connections.
Anyway, now I always prepare two separate books for similar projects. One for the actual application backend DB, one for the replicated data in a separate schema.
Data bugs are often considered hard to catch because we can only tell whether it is a bug by examining the final results - the prediction result (or intermediate results if optimisation is done correctly.)
Service
In my case I did not really spend much time on the development of the service itself, due to the simplicity of our need for the current iteration. Thus, I will not and could not go very deep into the subject. With such a simplistic setup, I feel there is not much difference from setting up a conventional web backend.
Architecture is simple:
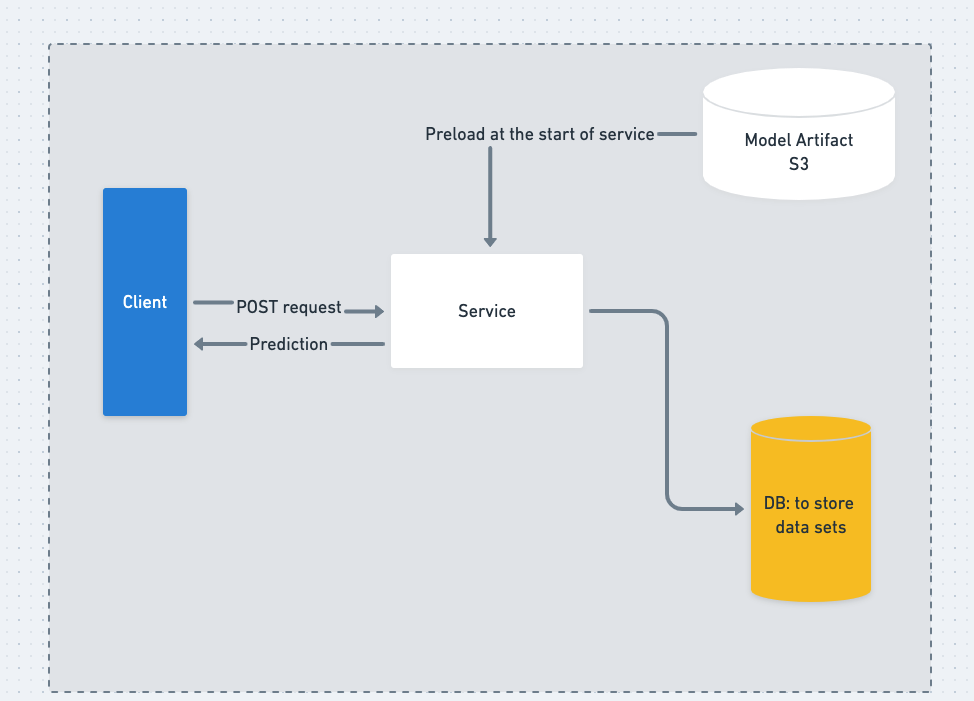
Personally I did not like ORM in simple projects so I have not yet tried integrating ORM with this dual-schema database setup.
Request rate
One thing I have to agree with the platform backend engineers (they are my users yes) is rate of requests, subsequently the responsibility of validating changes in the raw input. Ideally, we want to make a new prediction when there is a change in the raw input. In my case, I managed to persuade my colleagues to verify the input updates before calling my service, but it might not be appropriate for every scenario.
Model (Pre)Loading
Model artefacts could be huge in terms of size, so it is crucial (and common knowledge I guess?) to preload the artefacts as global and accessible by the service workers.
In the specific case of gunicorn , use the —preload option.
Docker image preparation
This should probably be discussed Part II, but personally I usually develop using docker directly. Some people prefer to develop outside of the containers, and then later on dockerize it. There are pros and cons for both approaches, but they will not be discussed here.
Assuming taking approach one (develop with containers directly), we often need to rebuild the image several times. That means if not carefully planned, we will waste a lot of time waiting for libraries to be built, which results in a discontinuity in thoughts as we switch to other projects. Thus, build a common machine learning base image seems a sensible choice. Of course there are several popular existing pre-built images for machine learning, but I have to decide to build everything either from source or pip, and it is definitely a good learning experience but a chaotic nightmare. Anyway I only recommend you to do it once and only once.
Summary
This is my favourite project as it was completely built by me - of course you get attached to our own work don’t you? :). I could image that the complexity and the size of the modules will grow when there are more requirements / data sets, and hope I had the chance to work on such projects in the future. Ultimately, I feel quite a few problems could be successfully addressed using established approaches from the conventional software engineering, with a touch of data sense to handle the potential variants.
More discussion on deployment for Part II, if I am not too lazy to write it, and I have only finished this post now because I started to forget what I have done one week ago (feeling old man).