DET Log 1: A first “byte” of Airbyte
In this article, I am sharing my first impression on the open-sourced almighty data ingestion tool - Airbyte.
I am currently on a week long leave after shipping our streaming pipeline
foundation in Q3, this break finally allows me to pause a bit so I could
fully focus on watching Dota2 The International thinking about the
data engineering scene strategically.
Data ingestion has always been an interesting component to me, collecting
data automatically into a database/warehouse/lake is a very convenient
remedy for my mild (yes, just mild) hoarding disorder. Therefore it is no doubt that
Airbyte has been one of the many data products that I wish to try, so I did.
Disclaimer: I have not used this tool to its fullest capability, I have left out certain features like CDC syncs, or performed a very robust load test, what I will do instead is to highlight some of the features that I really like (and provide reasons for it), and some of the concerns I have observed so far based on my unique and non-universal sets of needs when it comes to data ingestions.
The Good
Overall I think this tool is perfect for small teams or companies with a very small data engineering team, commonly observed at their initial stages. It without a doubt speeds up the data movements from the operational product environment into the offline (online/live is out of the question here since Airbyte is not for streaming) analytical environment with minimal efforts.
I will highlight some of the features that make this possible.
Configuration-based pipelines, with GUI
Over the years of practices I have come to realisation that building data pipelines is fun only when you are building something new constantly, it quickly becomes boring once the repetitive pattern starts, even with the help of a few for loops. I think it has very much established in the industry that we would want to dynamically generate data pipelines, or automatically generate data pipelines from scripts as much as possible.
What I have done recently in my day job is basically generating Airflow DAGs and Tasks based on a YAML git repository that got synced in a S3 bucket via CI pipeline, this makes adding/removing a pipeline extremely convenient, not mentioned the additional benefits comes with CI, such as validation logic and versioning.
Airbyte took a very similar approach, it does not only provide the YAML configuration option via their cli offering, but the application itself comes with a very nice GUI.
The GUI can be very useful under two conditions:
- Data replication is done on a requested basis - we only request what we needs, instead by default syncing everything from the operational databases or data systems
- The organisation is embracing a self-service culture, or at least in the data usage aspect - I would say GUI will be the most important pre-requisite to drive this culture. It’s hard to convince even more technical data analysts or data scientists to write YAMLs, it would be easier if the company is started with this culture. It also shortens new hires onboarding time and opens up more room for hiring when certain skills are not required. This miniatures the platform strategy many big techs are taking to a certain extend.
Handles long tail problem with SaaS APIs
We often need to ingest data from a third party SaaS product, via their raw APIs or SDKs. The SDKs can vary in terms of usability, and limited by the programming language used, plus it’s mentally draining for our engineers to build a custom Hook to a system just to bringing 30 rows of data from Zendesk.
Airbyte solves this with finesse, as an open-sourced tool it has a lot of community contributed connectors, saving your extensive amount of time to deal with integration. I think this is pretty obvious, so no further elaboration will be penned down here.
The Bad
However I do have some concerns, some of them can be found in the Github Issues, some of them are very specific to my current usage. I do want to stress again that I have not used the tool in production extensively so it’s purely based on speculations and other discussions online. I would not say these are critical flaws that make this product bad, it’s more like nuances that one might need to overcome to fit this great product into their stack.
Performance
Performance either on read or write is one of my initial concern, in particular against those often heavily used operational databases, when you have billions of records in a single Postgres table.
Per this discussion, it looks like you will have to create multiple connections to achieve parallel sync within a single database. Would this also mean that within the connections syncs are done sequentially? Of course this could still be overcome by dynamic YAML generations so we can still tinker a bit of configs and generate the correct set of tables in each connection, just need extra work.
Based on the official docs, the workers are horizontally scalable globally, but seems impossible to at connection level.
Sync jobs use two workers. One worker reads from the source; the other worker writes to the destination.
This most likely means that one connection would at most take two workers, but not more than that, if I understand this correctly.
You can’t devote a cluster of workers on either read or write process here, which is possible in other data system.
In Spark you might to something like a controlled parallelism allowing
each worker to read a partition of a table, by providing a list of predicates, but on the write side I believe the destination
databricks lakehouse will allow you to tap in the scalability of managed Spark.
Essentially I am not 100% sure that this is going to be a critical problem without trying it with production tables, since if incremental tables can be setup and if the incremental load is pretty manageable, the gain from boosting performance on read and write beyond one worker setup might be marginal. Nonetheless I think it would be nice to have similar options.
Abstraction Level
In Airbyte each pipeline or connection could sync one or more tables from the source, so each pipeline could be used to handle a set of tables that are similar in configurations, however this means that the configuration is not set at table level. Let’s say we have 100 tables, if we want to run everything concurrently, we need to create 100 connections. This would require us to create a different layer of abstraction of configs so we could manage this dynamically.
I would like to have a destination table level pipeline because in my current setup, we are using data lake(house), essentially we would want to have:
- Able to run (or have the option to run) everything concurrently
- Able to execute other optional post-ingestion actions, such as registering the lake table in Presto/Trino
The Solution
I will just propose a very high level solution here for the issue above briefly. Note that this might not be an issue at all for you based on your needs, and I would say with confidence that this will not be a problem for most teams. The solution is based on what I have proposed and created in Xendit, essentially revolves around a centralised configuration repository, what I called the Registra.
Overview
The Registra is a central storage table level configurations, tables that are in your main analytical storage, being either data warehouse or data lake, or lakehouse.
A rough flow will be like the following:
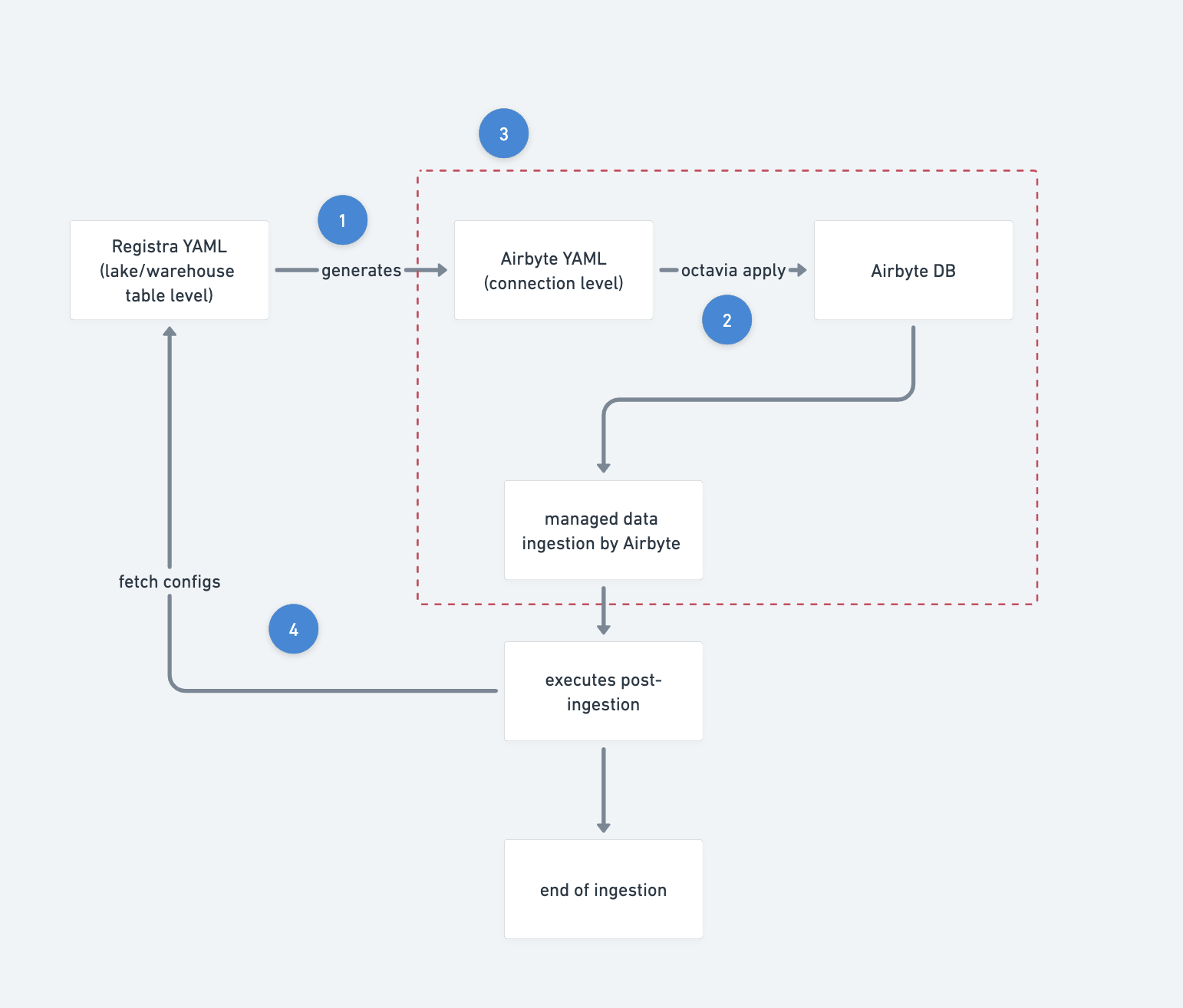
-
configurations are used and parsed to generate the Airbyte YAML files. We could easily introduce new config fields that helps group connections logically together, something like
cron_groups,connection_groupsat table level so eventually we know which tables can be grouped together into a single Airbyte connection, which (normally those heavy tables) requires it’s own slot in Airbyte -
Apply the generated YAMLs so the YAMLs gets recognised by Airbyte
-
Trigger the connections so they are online, and let Airbyte takes over the Data Ingestion
-
On a separate process, most likely in a separate orchestrator as well, you dynamically generate a list of tasks based on the same Registra YAML repo and use that to handle any post-ingestion operation
The above flow could be easily converted into a proper CI flow too, any changes pushed into the Registra repo will be the trigger and the rest can just follow.
Other directions
Besides YAML Github Repo based solution, the centralised configs Git repo could be replaced with a proper relational database too, which will enable you to better control on concurrent changes to the configurations. This will easily get you a decent self-service tool internally if a GUI is attached in front of that database.
Wait a second, we already have that self-service GUI comes with Airbyte that allows people to self-serve their data ingestion needs, would not this be a bit duplicated?
I would say the Registra is not just designed for data ingestion, it should be the central config and a single source of truth for tables in your analytical storage, including things that are not yet possible in Airbyte, and other things around the tables such as metadata, lineage, access control or archiving.
However if we are looking at the data ingestion step alone, it is a little bit overlapped because Airbyte has covered a lot of angles in the data ingestion aspect, any wrapping layers around it will not be very useful unless you have a very specific real use case. To reconcile this, we need to recognize that there are two sets of configurations here, one from Airbytes, in the form of YAML and eventually values inside Airbyte DB, one from Registra, in the form of YAMLs or DB values directly. The Registra YAMLs will be used to handle those specific stuff that can’t be done with Airbyte, where Airbyte configs will stay the same. In this regard we are opening up two entry points for configuration changes, one for data ingestion, done with Airbyte GUI, one for analytical table, done with Registra.
A typical user flow would be:
- I want to replicate this table, so I went to Registra GUI and setup the source, destination and destination configs
- I pushed the changes
- CI triggered, Airbyte YAMLs will be generated and connections will be registered automatically, after a while
- If needed, I could go into Airbyte GUI to further configure the ingestion changes, if not needed, the default setting should be enough to get my data into the destination
Yes I would consider this a bit confusing, but with this setup it is possible to integrate
many other open source tools into the data stack, centrally controlled from the central configs.
We have successfully integrated dbt into this setup where Registra configs sits side by side with the entire dbt YAML configs,
connected using the path of dbt models.
Concluding Remarks
At high level I feel Airbyte is a great tool for companies / orgs that:
- initially start to build up their analytical platform to extract data insights
- does not have a huge amount of data in their operational databases
- are not financially stable enough to support a relatively complete data engineering team
With Airbyte, one experienced data engineer, or even generic software engineer could probably handle the data ingestion needs of the team and unlocks more potential in data usages downstream. However, I would still caution every team to examine their specific data ingestion needs and evaluate whether Airbyte is something worth trying. There is little gain from converting some of the existing working pipelines, but it does help save the time of reading different API Docs when integrating a new data sources like Salesforce or Zendesk.
Despite such tools are making data engineers more replaceable (my job alike) over the time, I still feel
this is good for the world overall. It’s just the wheel of history, you do not counter that popular and cliche term
these days, democratize data engineering, you just embrace it, but that discussion demands a separate blog post.
Hope this article is helpful for you.