DE Log 9: Extend duckdb beyond the single player mode, by just a little bit
Yet another take on poor man’s lakehouse / or how to NOT contribute to Databricks’ IPO success even though it seems inevitable.
Overview
Recently, I asked a friend to help me acquire a NAS server with the requirement that it could run extra services. That was about three months ago, in the past few months, I’ve been learning the fundamentals of navigating the TrueNAS Scale system. It wasn’t until I discovered jailmaker that I could start building something concrete. Staying true to typical human behavior, I chose to build a lakehouse since, well, I’m a data engineer, and I wanted to use this opportunity to play around with all the popular tools I’ve heard about in the past few years that I have yet tried during my day job.
In this blog, I’ll cover the setup of a poor man’s lakehouse, a solution that is slightly more mature than a POC setup but definitely requires further polishing if you wish to run it as the main lakehouse for your startup. This won’t be a strict step-by-step tutorial, but I’ll outline as many technical details as possible to make it reproducible. My immediate goal is to set up a decent lakehouse to host the financial data collected from the internet, which will help with my options trading.
What Does Poor Man’s Mean?
As the name suggests, it should be cheap upfront (not so much in human effort, but that’s beyond the scope of this discussion). You literally pay nothing for software licenses by using open sourced projects as much as possible. If you already own hardware to host it, you’re in luck! However, you’ll need to invest a lot of time making things work. This is why I wouldn’t recommend this unless you’re really into the topic and doing it as a hobby (like me) or just looking for a challenge.
Ideally you have an unused computer sitting somewhere in your house, with a decent amount of RAM and collecting dust, and a solid CPU (you need to perform data transformation after all). In my case I have the NAS built with 128GB of RAM, so I could use it for more than just a NAS server.
Why Extend it Slightly Beyond Just a POC?
While a POC will work for my homelab use case, there are countless articles that demo the integration of DuckDB and DBT or DuckDB and Delta. However, as a practitioner who actually has a day job as a data engineer, I need to try it myself to make a sound judgment. Blindly following online articles is like putting faith in AWS’s Redshift benchmarks against Databricks — optimistic at best. Additionally, I wanted to see if DuckDB could function as a pure compute engine, similar to Spark. If successful, it might even replace Spark in future projects — saving tons of money on paper (and earning some of that all-important visibility that everyone seems to chase, for better or worse 🙂).
Why a Lakehouse?
The trend is clear: with the decoupling of compute and storage and the rise of Open Table Formats, I personally don’t see the general need of a traditional batch focused data warehouse anymore — except maybe for legacy compatibility and for ultra-low latency queries. If I were to start a new company, a Lakehouse will be a safer choice in most cases. This might sound a bit extreme and narrow-minded, but my work primarily involves building new data platforms for teams or transforming/migrating existing ones. So, when I decided to build an analytical platform for personal use, I chose the lakehouse approach with a different stack to see if I could build something similar to my profession-grade stack entirely with open-source tools.
For paid work, though, I’d still go for Databricks — gotta keep the team sane and weekends free.
Enough BS, let’s dive to the details..
Design
High Level Architecture
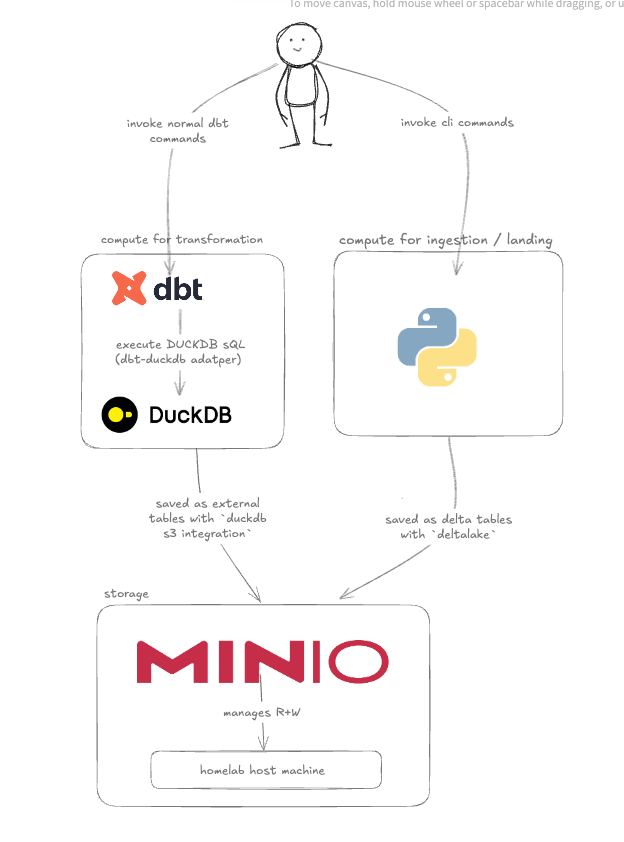
First let’s talk about the high level design, and to repeat our goal: to set up a lakehouse architecture that decouples compute from storage, using open sourced tools to keep costs low and flexibility high so that if we want to migrate to something like a cloud setup, it would be less painful.
I picked the following tools:
- uses DBT for data transformation
- DuckDB as a pure compute engine (think of it as your “query engine”)
- NAS File system and MinIO as the storage layer
This setup will allow me to work with large datasets without needing a traditional data warehouse or the complexity of Spark clusters (unless your dataset is truly biggy big then perhaps you need spark afterall).
In the next sections, I’ll dive into how each of these components fits into the architecture.
Decoupled Compute and Storage
One of the key design goals of this architecture is to decouple compute and storage. This means we want to use DuckDB purely as a compute engine, while the actual data storage will be handled separately through MinIO (or potentially other object stores). This is achieved via External Tables. Though frankly speaking, it’s a bit hard to get duckdb to work with external tables via dbt like what we used to on Databricks + Spark.
Why External Tables?
The main reason here is to allow concurrent read on the actual data from different system, thereby bypassing the DuckDB single player constraint. With external tables, data can be accessed from various platforms (like Trino) without being tied to a specific storage format or location. It also allows for avoiding certain constraints, like file locks, which can happen when reading from a DuckDB file directly (e.g., when using tools like Datagrip, it will hold the file lock even you specify the mode to be read-only , thus preventing any writing from the dbt side).
How it Works (data flow)
Let’s assume we are using the standard medallion architecture. You have a landing layer before the bronze layer, followed by silver and gold.
Note, there is an limitation that dbt-duckdb does not yet support writing of Delta Table, or any Open Table Formats yet. Hence, the write from dbt are all done using Parquet External Table, this also means that incremental write via MERGE command will not be available either. There are interesting workarounds online that talks about
persisting models at partitions level to achieve incremental load, but for my use case I choose to FULL RELOAD everything everyday.
- Your python scripts will land the data into landing layer in Delta Table format (pandas / polars → Delta)
- Landing → Bronze:
- Read: DBT will instruct DuckDB to read data from external delta table with the
dbt-duckdb-deltaplugin. - Write: DBT will instruct DuckDB to write into bronze layer as an external parquet table
- Read: DBT will instruct DuckDB to read data from external delta table with the
- Bronze Onwards:
- Read + Write: to be done via standard external Parquet tables
I am using Delta because I am more familiar with it, but I am eager to migrate to other formats if they are supported by duckdb.
Distributed Read: DuckDB File as a Catalog
If you use dbt-duckdb as intended / in single player mode, you will have to hold on to that single connection during your write process, which prevents you from reading using standard GUI tools (I have tried it via DataGrip and Metabase, both will fail).
Since we are using DuckDB External tables, the data is actually not saved in the .duckdb file, we can easily duplicate the DuckDB file as if it’s a data catalog. This is inspired by this article. The idea is if I duplicate the catalog file after each write on dbt side, and DataGrip (or whatever reading client you are using) will read using this duplicated .duckdb file, we will have no problem accessing the data while further execute dbt transformation concurrently. The actual duckdb file will be used only for registering table namespace and the actual reading of data will happen between the compute engine and the storage layer, so the size of the file is super small and portable.
Obviously this is a pretty simplistic way of expanding the default concurrency support of the native DuckDB, and to enable distributed writes (writing from multiple containers / host to the same storage, and to the same duckdb catalog) requires more work and is much more complicated, and so far I don’t think it’s possible without writing a custom layer of application / service to manage a pool of duckdb files / locks. Personally, i think DuckDB has some potential to become the defacto production ready Small Data compute engine, I have not really checked MotherDuck in detail but probably that’s what they are doing.
Regarding catalogs, there are indeed the newly open sourced UC and iceberg catalog, however none seems to be working with Duckdb perfectly yet. and given my use case, I will be more than ok with a crippled distributed read setup. No distributed write at all (it means all Airflow tasks will need to be executed sequentially).
MinIO for distributed write (Optional)
I have mentioned above that I will be more than happy to accept a sequential write, but I will still want it to be semi-distributed (sequential write from a few hosts). For that, instead of relying on the native linux file system i have in my NAS server, I turned to MinIO. Reasons being:
- you have an easier codebase to maintain - you do not have to manage directories like mkdirs all the time, permissions are farm more easier than SMB / NFS shares
- able to share across different hosts if you ever have to. In my case even though it’s a homelab project, I have set aside one jail for development (when I m away from home and on mobile data), and one jail for production. Enabling write to the same storage layer from both hosts will be extremely convenient
- easier to migrate to cloud if you ever have to later
- You actually get an UI for managing your files, like what happened in S3
- Minio setup is somewhat simple if you are using docker-compose, thus it’s worthy of the effort to use it
However i did have some issue with the minio SSL when integrating with duckdb and dbt. This indeed presents a blocker for real production usage and thus I have disabled all SSL in both MinIO and Delta table read. I hope to revisit this and it will be solved by others in the future.
Some other thoughts
Some other features i have not tested but i think possible to be done:
- Incremental loading / merge into: despite being a little bit too far fetched for my current use case, i would definitely revisit this when duckdb enables real external writing capabilities with any one of the existing Open Table Format. One potential workaround is to generate dbt model at partition level, essentially going back towards the old hive-style data management for delta. It’s a bit backward but I think it will work just fine with proper orchestrator logic
- File compaction and other Delta specific features like liquid clustering - a bit too early for my use case, but I think i will need it eventually and it should not be very hard to implement
- If I really really need a fully working production ready lakehouse that enables distributed write and read, I can still turn to self hosting a spark cluster, which sounds really annoying but I think it’s not that hard anymore in today’s landscape.
Integration snippets
in this section, i will talk about some integration configuration to provide a starting point for anyone wish to replicate my setup.
Write from Python memory to Delta Tables in MinIO
Use the write_deltalake method from deltalake package together with the storage options.
The key-value pairs documentation is very hard to locate online, I have spent some time to make MinIO work with the setup below.
e.g.
from deltalake import write_deltalake
storage_options = {
"AWS_ENDPOINT_URL": config.remote_storage.STORAGE_ENDPOINT_URL,
"AWS_ACCESS_KEY_ID": config.remote_storage.STORAGE_ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": config.remote_storage.STORAGE_SECRET_ACCESS_KEY,
"AWS_ALLOW_HTTP": "true", # Required
"AWS_S3_ALLOW_UNSAFE_RENAME": "true",
}
write_deltalake(
table_or_uri=<delta_table_dir>,
data=<your_pyarrow_table_obj>,
mode="overwrite",
schema_mode="overwrite",
storage_options=storage_options
)
DBT setup
There are mainly 3 things to consider, the profile.yaml , which is used for ensuring successful authentication to MinIO, and dbt_project.yaml and the macro for external_location which are crucial for automatic creation of external tables.
In your profile.yaml, you should declare plugins with delta and specify the secrets. this corresponds to the s3 secrets in DuckDB setup. If you choose to use iceberg, find the corresponding extension in dbt plugins.
Another thing to note here is the path , where your .duckdb file has to be on your local file system. This is essentially the catalog of your current dbt session. I don’t see an obvious way to make this accessible / writable in a remote sense.
Now for sequential write, you can have a single host pointing towards a single .duckdb file, and then duplicate it layer for distributed read.
project_name:
target: "{{ env_var('DBT_TARGET') }}"
outputs:
dev:
type: duckdb
path: "{{ env_var('PROJECT_ROOT') }}/dbt.duckdb"
plugins:
- module: delta
threads: 2
extensions:
- httpfs
- parquet
secrets:
- type: s3
region: ap-southeast-1
key_id: '<enter your key id here, pass in with env var>'
secret: '<enter your secret here, pass in with env var>'
endpoint: "xxx.xxx.xxx.xxx:port"
url_style: 'path'
use_ssl: 'false' # adjust for your case
schema: dev
Typically you will need to declare the external_location manually for each model to ensure your model to be written as external table. However this can be quite tedious, and we can very well utilise dbt jinja syntax to make this less painful.
In your dbt_project.yaml, declare the general model config as the following:
models:
finget:
+external_root: "{{ env_var('EXTERNAL_ROOT') }}"
silver:
+materialized: external
+mode: "overwrite"
+schema: "silver"
bronze:
+materialized: external
+mode: "overwrite"
+schema: "bronze"
And in your macro folder, override the original duckdb external location macro to be:
{% macro external_location(relation, config) %}
{%- set default_schema = target.schema -%}
{%- set location_root = config.get('external_root', validator=validation.any[basestring]) -%}
{%- set identifier = model['alias'] -%}
{%- set fqn = model['fqn'] -%}
{%- set pkg_name = model['package_name'] -%}
{%- set format = config.get('format', 'parquet') -%}
{%- set model_layer = fqn[1] -%}
{%- if location_root is not none %}
{%- if config.get('options', {}).get('partition_by') is none -%}
{%- set identifier_ending = identifier ~ '.' ~ format -%}
{%- else -%}
{%- set identifier_ending = identifier -%}
{%- endif -%}
{%- if default_schema == 'prod' -%}
{%- set location = location_root ~ 'main' ~ '/' ~ model_layer ~ '/' ~ identifier_ending -%}
{%- else -%}
{%- set location = location_root ~ 'main' ~ '/' ~ model_layer ~ '_' ~ default_schema ~ '/' ~ identifier_ending -%}
{%- endif -%}
{%- endif -%}
{{ log('Writing the data files to ' ~ location, True) }}
{{ return(location) }}
{%- endmacro -%}
Essentially, once we have set the location_root / external_root to be something like s3://bucket-name/ or a local path like /mnt/data/ , for each one of your model declared in external materialization mode, the actual path will be generated based on environment and the model name automatically, thus saving you the hassle of declaring it inside every model.
At this point, all transformation (dbt build commands) will function properly.
And lastly, for constructing the dbt sources, it took me a while to realise you need to include the
actual scan function in the declaration, like below (note on the usage of delta_scan which directly
invoke duckdb-delta extension. )
sources:
- name: staging
tables:
- name: table_1
- name: staging_2
tables:
- name: table_2
meta:
external_location: "delta_scan('s3://bucket/landing/xxx/table_2')"
Couple of limitations here to note:
- this only supports writing of standard data format such as parquet, csv etc. the code example uses parquet. This is mentioned above being part of the writing limitation for duckdb
- I have not tried writing real partitions with DuckDB. It is supported but I have no idea whether it’s possible to integrate with this setup.
Conclusion
This blog provides a potential “low effort” way of extending DuckDB read capabilities beyond single player, which are typically more prioritised than distributed write in a homelab setup.
There are several workarounds presented online for distributed writes, most designs have been already highlighted in the official doc here.
Hope you find this helpful and informative.